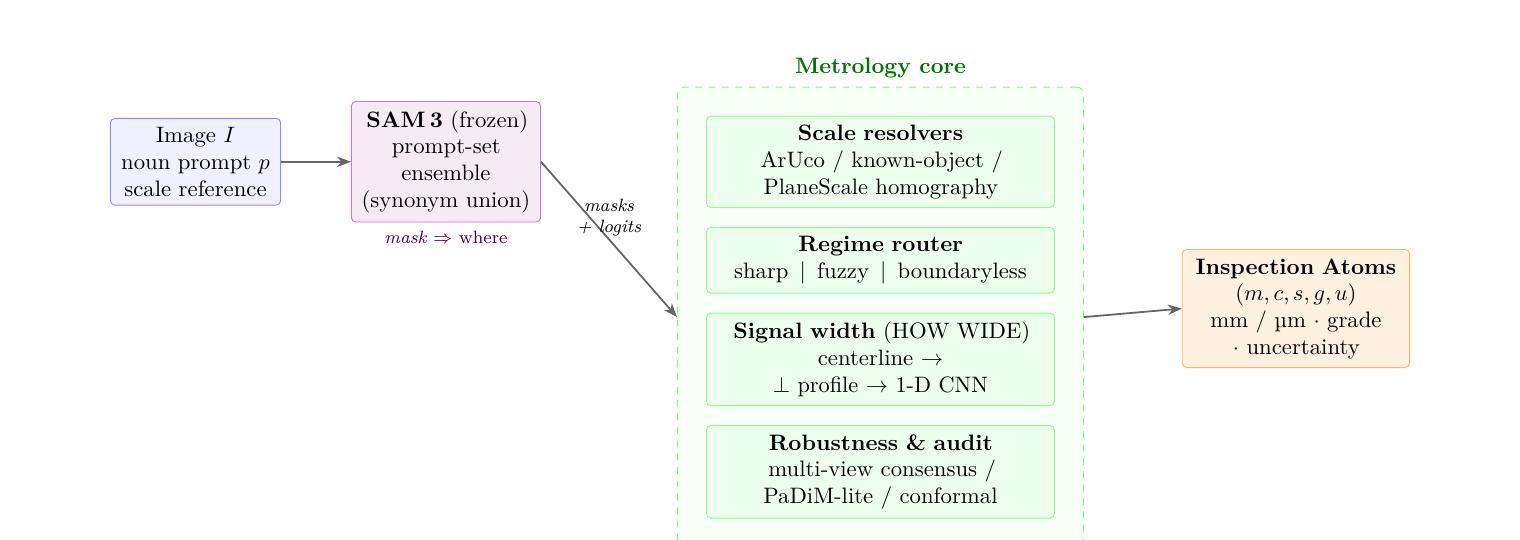
Architecture
A frozen perception front-end, an explicit metrology core
A frozen SAM 3 backbone (wrapped in a synonym prompt-set ensemble) proposes instances; the metrology core converts pixels to audited physical units. Only SAM 3 and four small heads hold learned parameters — none touch the scale arithmetic.